
TL;DR
We introduce the Filter Extractor, an SLM model that extracts structured filters from the query for the given field. This lightweight model is significantly more cost-effective and consistently faster than generic LLMs like GPT-4o, while maintaining high accuracy. You can try it for free. For customized solutions, including fine-tuning or on-premises deployment, please contact us.
The (Metadata) Filter Extraction Task
Search engines like Elasticsearch and Pinecone not only index text or vectors but also support the storage and structured querying of metadata (Pinecone docs, Weaviate docs). Users can use this functionality to filter search results, ensuring a closer alignment with their specific needs. For example, in the image below, metadata filters are applied to specify the brand and price range in a search service.

While lexical search once dominated, semantic search has become the new standard. Consequently, users now tend to search in natural language, expecting the system to understand and respond to their queries directly. The challenge arises when users express their metadata requirements in natural language rather than structured queries, leading to potential mismatches between user intent and the system’s capabilities. This often results in user frustration and confusion about what the search engine can actually handle.
To address this issue, we present the Filter Extractor, which extracts metadata filters from natural language queries. Given a query and a metadata field, the Filter Extractor generates structured filters. For instance, from the query, “Find articles about the impact of large language models on the economy published in 2024,” the model extracts the filter >= 2024-01-01 AND <= 2024-12-31 for the “Published date” field.
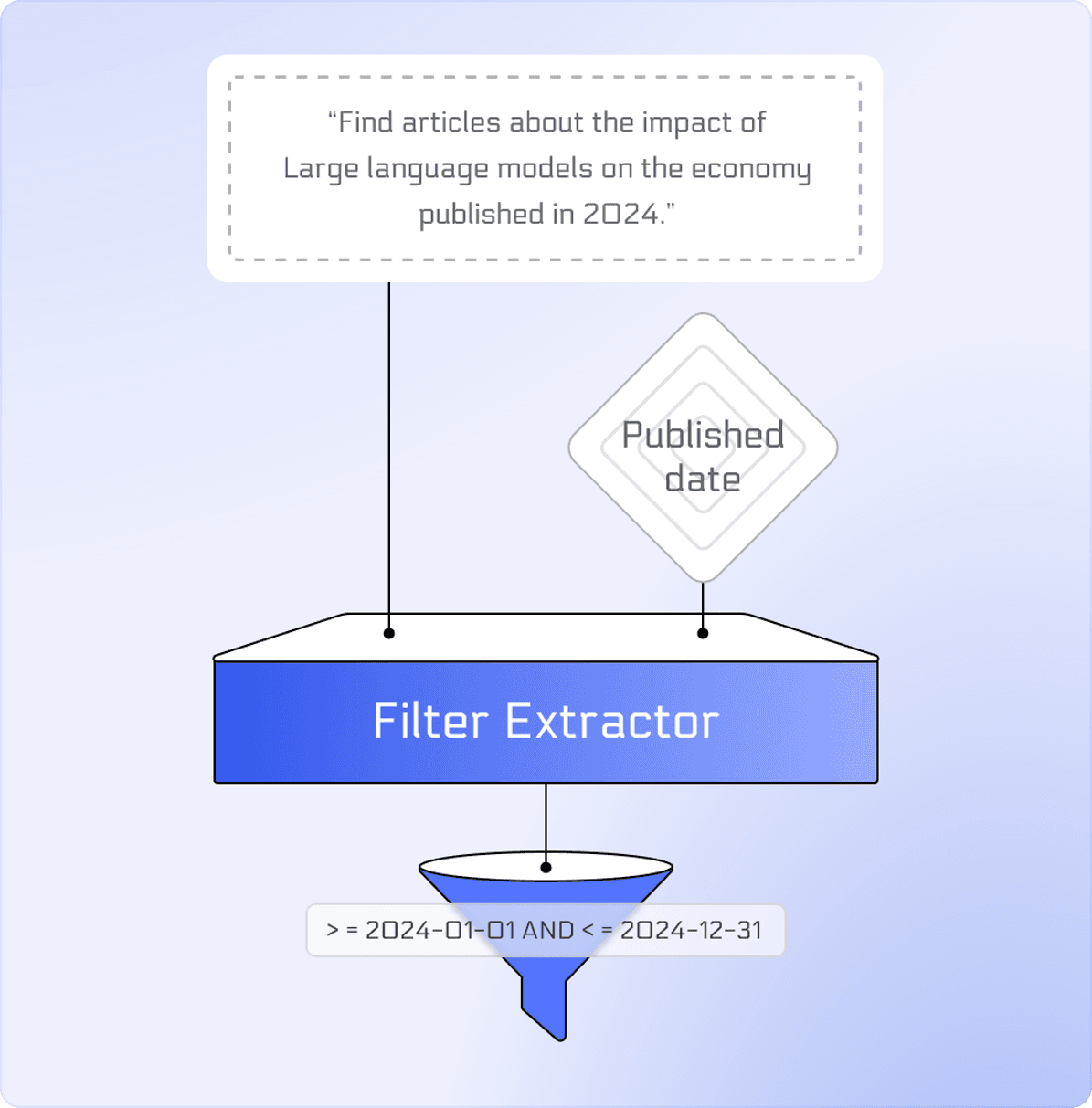
To ensure low latency in search services, the Filter Extractor processes one field at a time. Of course, your metadata schema may have more fields, in which case you can call Filter Extractor for each field in parallel.
Why a Lightweight Model is Essential
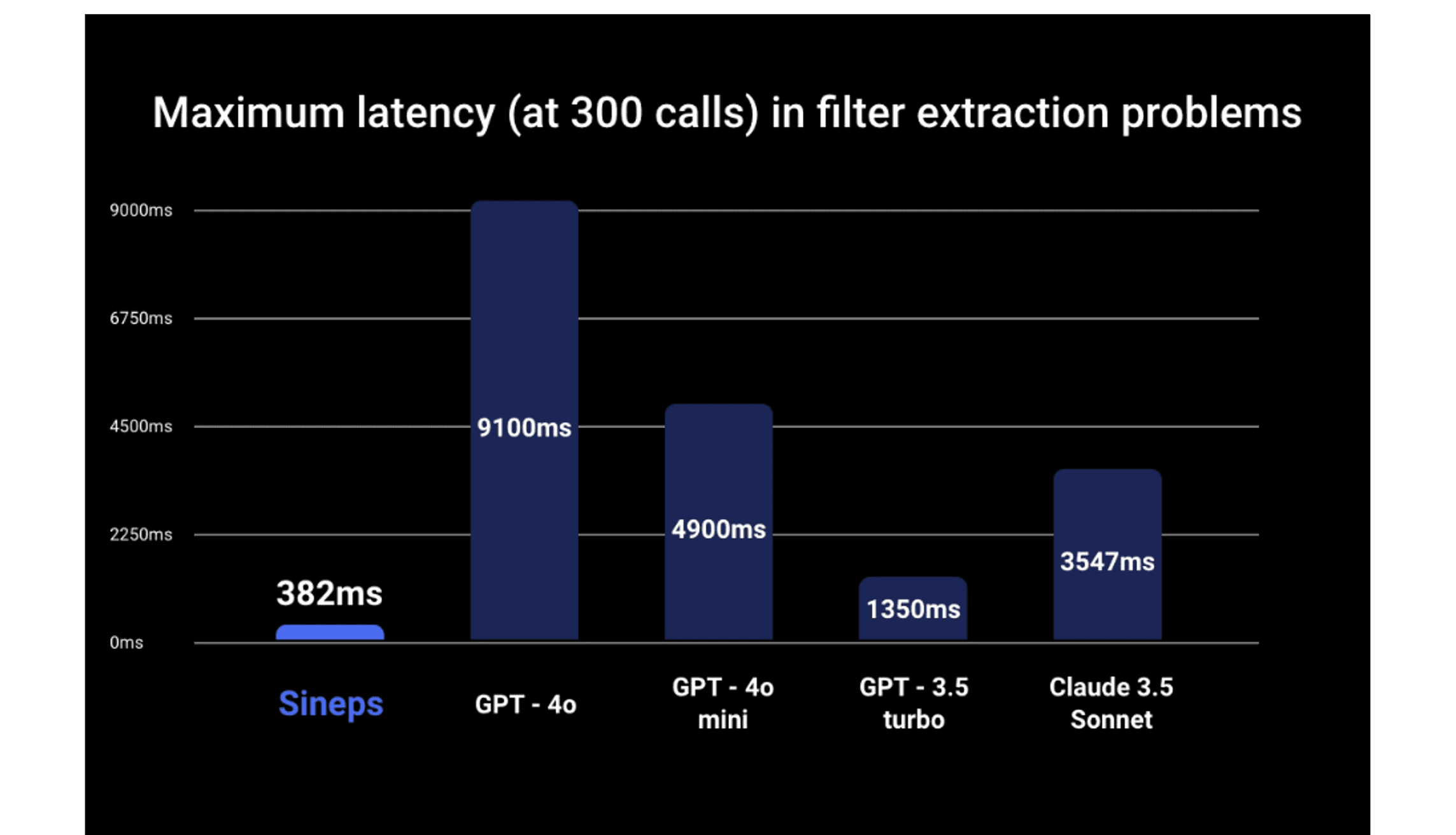
Speed is critical in search engine services. Users tend to perceive systems as slow if total latency exceeds one second, leading to decreased satisfaction. Therefore, when addressing the Filter Extraction task, latency must not exceed a few hundred milliseconds. Consistent latency is also vital for service stability, and we found that generic LLMs can suffer from high tail latency, making them less suitable for this task.
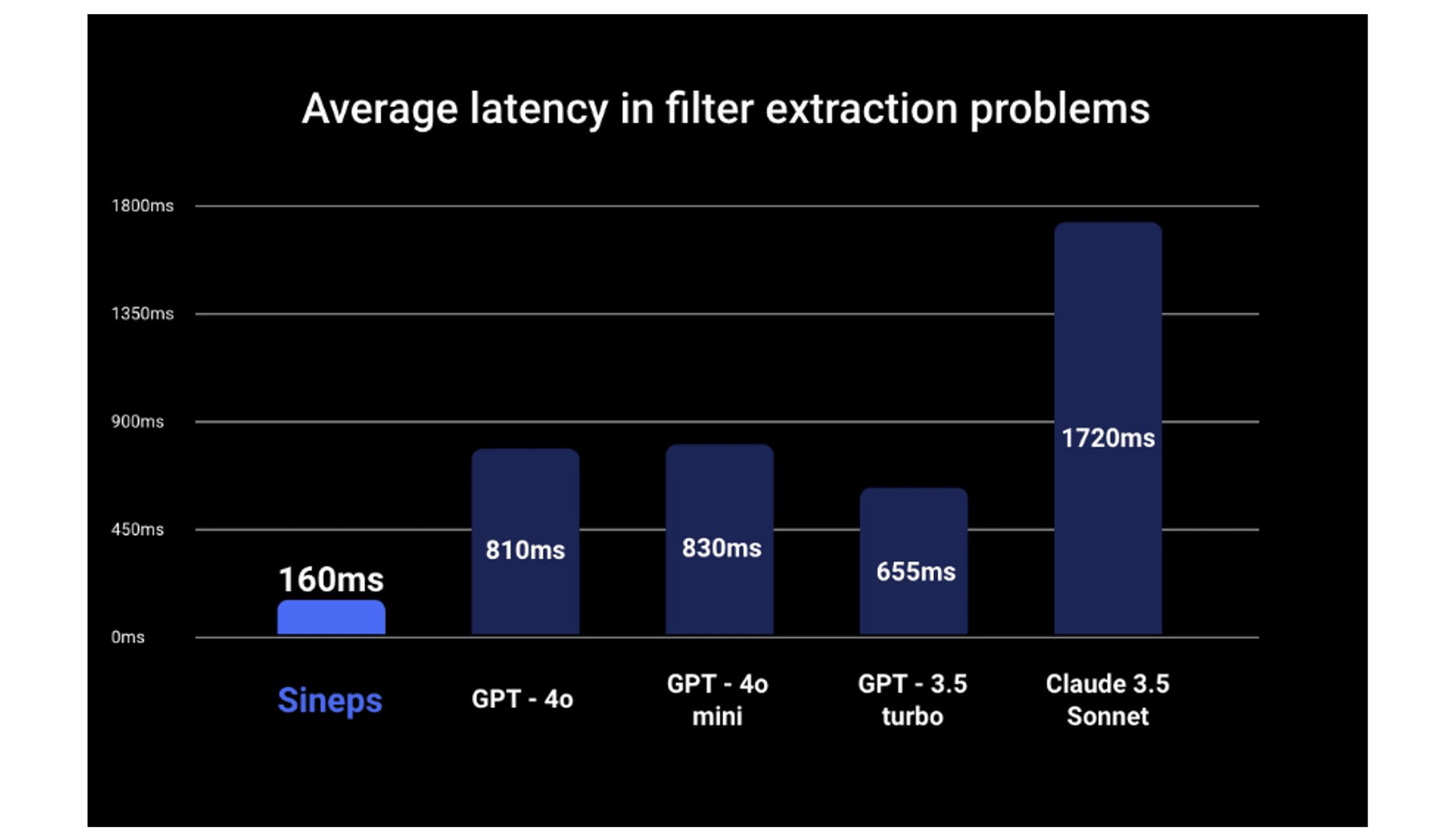
In experiments conducted over 300 iterations, the Filter Extractor was, on average, 5.1 times faster than GPT-4o, with a maximum speed improvement of 23.8 times. Compared to the recent lightweight model GPT-4o mini, the Filter Extractor was 5.2 times faster on average, with a maximum improvement of 12.8 times.
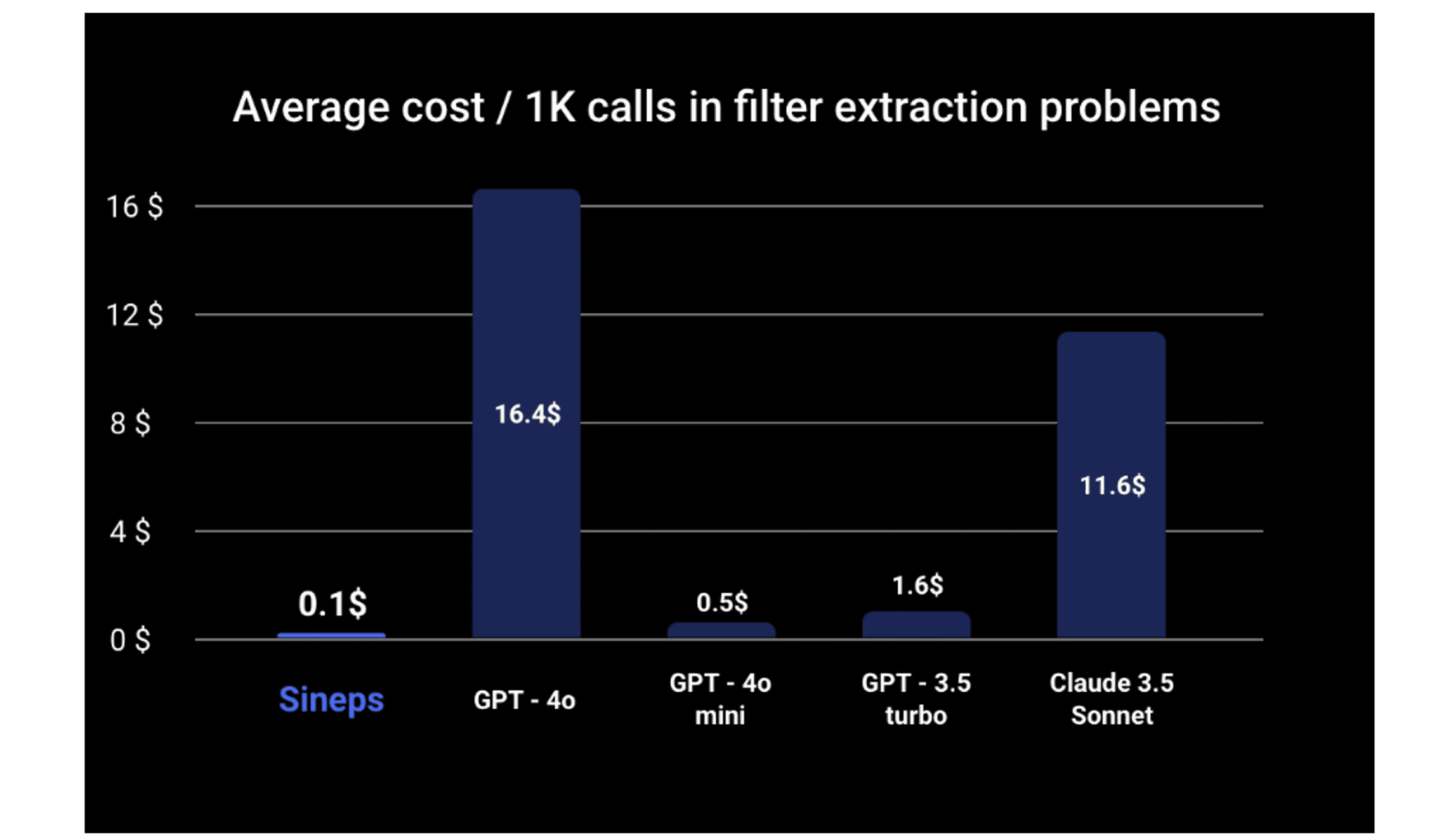
Cost efficiency is another key consideration, as the model is frequently invoked. The Filter Extractor is 164 times cheaper than GPT-4o and 5 times cheaper than GPT-4o mini.
Capability Scope
Our model supports operators compatible with various vector databases like Pinecone and Weaviate. We designed it to handle string, number, date, and list types as field values.
For date fields, users sometimes query based on relative time frames like “the last 5 years.” To accommodate this, we’ve introduced a current_date placeholder. Here’s an example:
Additionally, the model can handle unit conversions when the units assumed in the field differ from those in the query. For example:
For more details, please refer to the documentation.
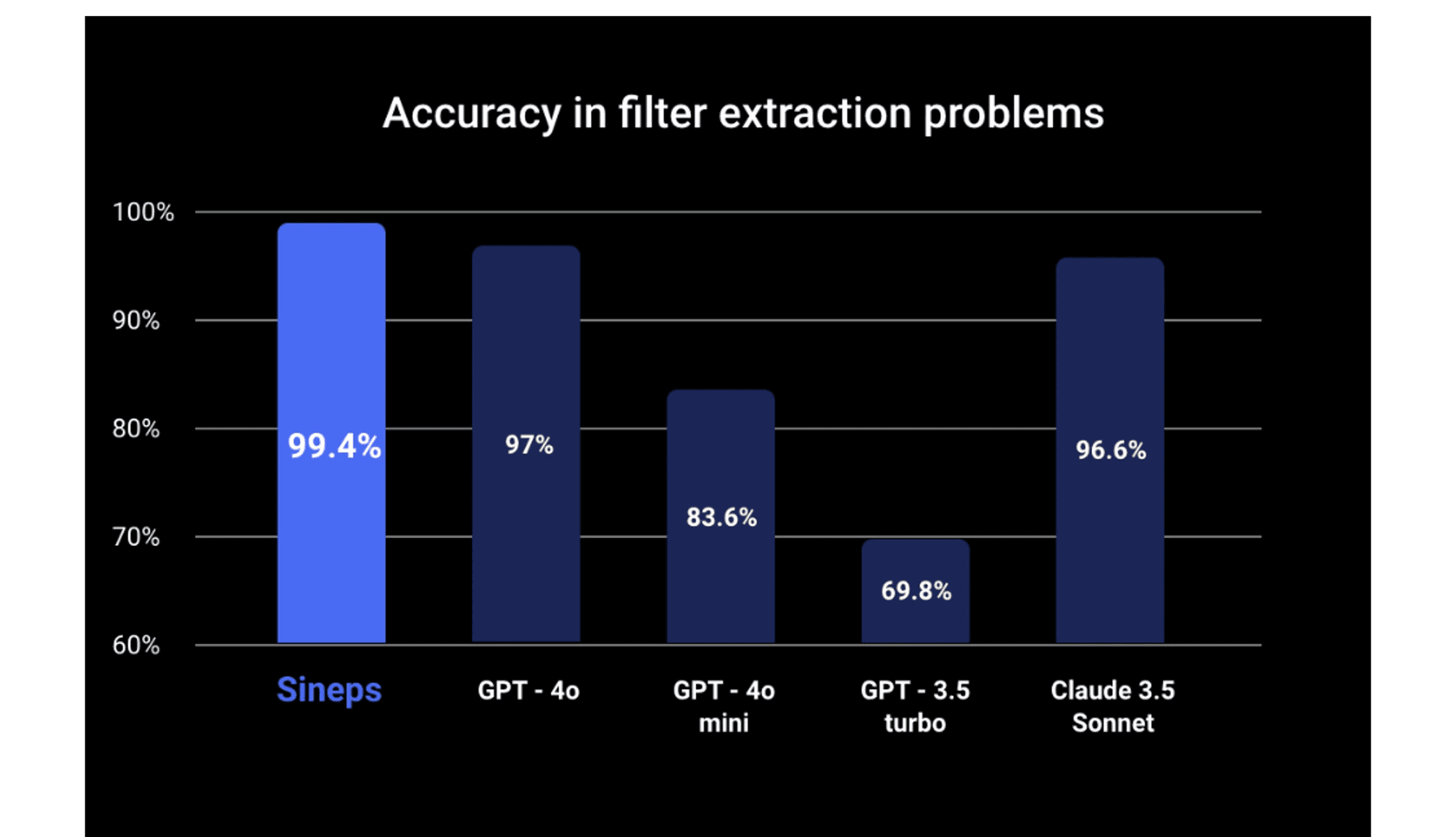
Accuracy
For the Filter Extractor to be a viable alternative to generic LLMs in AI products, it must deliver comparable accuracy. Our tests indicate that it performs at a similar accuracy level to GPT-4o and Claude 3.5 Sonnet on our custom datasets including publicly available filter extraction examples from the web. We also conducted analysis and found that most of the errors are ambiguous or due to dataset noise.
The Filter Extractor is trained to support multiple languages: English, Chinese, French, Korean, Spanish, Italian, and Japanese.
For specialized domains or cases involving private data, fine-tuning may be required. In such cases, feel free to contact us.
Training
We trained the Filter Extractor using a synthetic dataset that was created to ensure the model performs well across a broad range of domains. This dataset includes a variety of characteristics to enhance the model’s generalization capabilities.
To achieve high performance in multiple languages with low inference time, the Filter Extractor is fine-tuned from Gemma2-2B.
API Service
To make the Filter Extractor easy to use, we offer it as an API. The service is powered by optimized hardware and an inference engine designed for efficient performance. Below is an example of using our API.
Try it for free!
During our Open Beta period, you can use the Filter Extractor for free. Even after the official launch, a trial version will continue to be available at no cost. Visit here to try the Filter Extractor.
Who we are
We develop solutions for cheaper, faster, and more reliable AI applications. In these days, many AI products rely on LLMs, and the demand for LLMs is only expected to grow. Generic LLMs like GPT-4o are powerful, but using them for every task is inefficient in terms of time and cost. We offer a range of tools designed to address these inefficiencies, including the Filter Extractor, which we introduce here. Please visit our website to explore our services.